ETOOBUSY 🚀 minimal blogging for the impatient
A Quest for Voronoi Diagrams - 1. The Problem(s)
Voronoi diagrams started fascinating me a couple years ago… and I’m still trying hard to grasp how to manage them properly!
Where It Started
As it often happens, it all started playing.
This time I was playing by solving programming problems in CodingGame (which I strongly recommend, by the way, if you like programming). Some puzzle might require to get the nearest location where there is something, and this is where Voronoi diagrams usually pop up.
In a nutshell in 2D, given some fixed sites (e.g. where your possible targets are located), the Voronoi diagram represents how the plane can be divided so that each site is surrounded by a region of points that are closer to that site more than every other. Something like this:

So, for example, any point in the gray area in the low-left corner is closer to the black dot inside that area than - say - to the black dot inside the pink area immediately above on the left border.
… Now I Have Two Problems
It turns out I never really used Voronoi diagrams in CodingGame, at least not so far. Never say never. There are a couple of reasons:
-
first of all, there’s no pure-Perl implementation that I could find. Well, of course I could think of implementing it, but this led me to the second reason…
-
using the Voronoid tessellation is not exactly straightforward. Even if I could land on a good description of all polygons associated to each site, I would still have to figure out how to find the right polygon for the generic query point. There are of course algorithms to do that (we’ll get there, hopefully), but still.
Long story short, using Voronoi diagrams to get the closer site efficiently actually involves two algorithms:
- one to compute the Voronoi diagram efficiently, and
- one to query the diagram with a generic poing, again efficiently.
It’s a lot of work… and I didn’t invest the time. Two years ago, at least.
Being Honest
To be very, very honest: if it were very easy to implement the first algorithm, I would have probably done that already and proceeded to the second. It turns out that getting the Voronoi tessellation right can be quite tricky. This is being honest with my willpower.
But.
We have also to be honest with another fact: the most famous algorithm around, one which I think that today is almost always used and implemented, is a bit complicated and also… a mess to get info about. I’m obviously talking about the algorithm by Steven Fortune described in article A sweepline algorithm for Voronoi diagrams, published in 1987.
Or am I?!?
Fortune’s Algorithm Is Not What Most People Think
Taking a step back, I turned to Wikipedia’s page on Fortune’s algorithm to take a look at it. Please note: the link is to an hopefully obsolete version of the page in Wikipedia, more or less the one I read in the beginning of my quest. And it’s a mess.
Long story short:
-
the algorithm’s description is about a sweepline that eventually computes the Voronoi diagram. It uses sections of parabolas cleverly assembled in a shoreline to allow for using a sweepline algorithm, but of course it’s a description and something more formal can help;
-
the algorithm’s pseudocode is about a sweepline that eventually computes the Voronoi diagram, BUT… it has nothing to do with the one in the description! As a matter of fact, it’s a copy-paste from article An Efficient Implementation of Fortune’s Plane-Sweep Algorithm for Voronoi Diagrams by Kenny Wong and Hausi A. Müller, which is inspired to the original algorithm described by Fortune.
To add misunderstanding to confusion, the picture associated to the description shows a sweep from left to right, while the pseudocode is about a line that goes from bottom to top!
Practically all implementation and blogs I found around refer to the shoreline of parabolas description and specifically indicate that as Fortune’s algorithm, which is confusing at its best and about wrong according to the algorithm’s pseudocode.
In these cases, I find it helpful to look directly at the original source, i.e. Fortune’s article. I have to say that it’s a clever piece of maths (we will get to that shortly), but a few things are pretty evident:
- the shoreline is nowhere to be found
- there’s no parabola in it, but hyperbola instead!
So, arguably, a whole lot of people are referring to Fortune’s algorithm without having really read it. It took me some time to digest this, I couldn’t believe it.
What Fortune Really Says
Fortune started from the consideration that using a sweepline algorithm directly is not straightforward because at any time during a sweep only sites’ positions are known, not all intersections between segments (a.k.a. vertices) which are also points of interest. Alas, most of the times a vertex’s position can only be found after analyzing a site that is beyond that vertex. If only there was a way…
Well, Fortune found a way. He designed a clever transformation of the
plane that makes it finally possible to use a sweepline (i.e. a line
that sweeps the plane only moving in one direction) to get a division of
the plane that, when counter-transformed, provides the Voronoi diagram.
The transformation is called *; it is not one-to-one everywhere, but
it is indeed one-to-one where it’s needed, i.e. on the Voronoi
diagram.
Fortune’s algorithm is described after a considerable amount of maths that demonstrates the properties of the transformation condensed in the previous paragraph. The algorithm is described in about half a page and is, indeed, quite similar to the pseudocode of Wikipedia’s page, although it at least takes the time to describe all symbols. Thanks!
From my limited capabilities, though, I’d say that the algorithm in the
original paper is not really immediate. One key part - finding the
site in the already computed diagram where a new site would fall if
it were a regular point - is described very synthetically altough it’s a
key passage to ensure the complexity constraints of the algorithm (n
log(n), by the way).
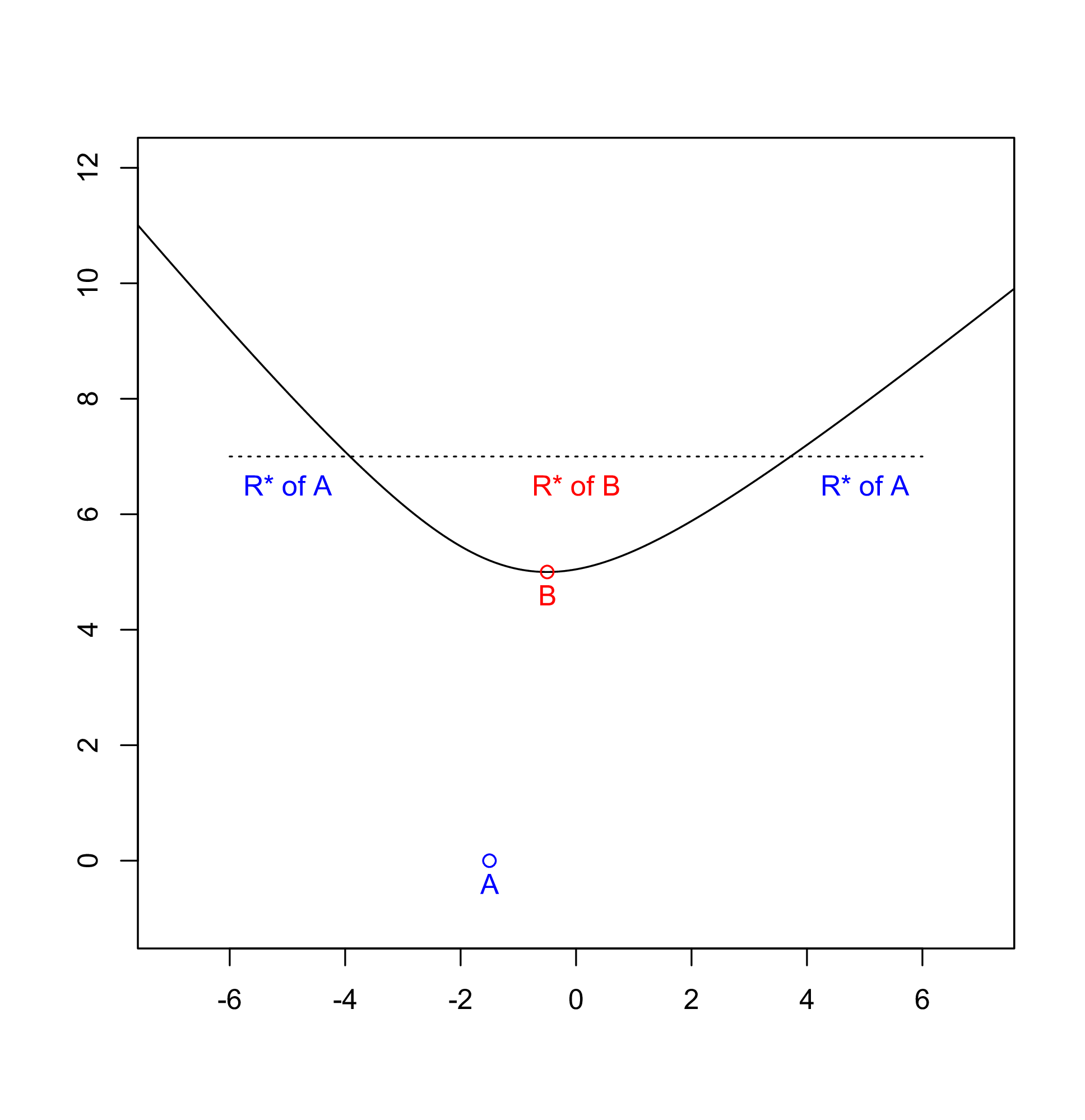
Also, there’s something super-confusing in the algorithm’s description: a sequence of regions (actually, sites) and dividing lines is said to be ordered by the x dimension, and yet it can have the following arrangement:
R* of A C(BA)- R* of B C(BA)+ R* of A
How on earth this is ordered by the x coordinate is beyond me only by the description in the algorithm. It turns out to be true, of course: just look at the following picture and concentrate only on the hyperbola arcs (which can be, indeed, be ordered by the x coordinate).
What Fortune Implemented
After having looked at the paper, a look at the implementation was due… and another problem popped up. Fortune’s page at the Bell Labs has disappeared, probably due to some restructuring of their website, and it’s somehow difficult to find the code. Luckily I found it in two places:
- one in Netlib’s page on Voronoi diagrams
- one in Archive.org’s mirror of Fortune’s homepage at Bell Labs
The code is… enjoyable, although a bit messy by my wishes.
Wrap Up and Final Notes
This ends this first chapter of my quest to understand Voronoi diagrams, how to implement them and how to use them. Lessons learned so far:
-
what is dubbed as Fortune’s algorithm is most probably not from Steven Fortune, although it probably started from there (if anything, Fortune has the merit of showing that a sweepline apprach was possible)
-
Wikipedia’s page on the algorithm is, at best, a total mess
More to come!
Some final remarks:
-
the original article was published in 1987 in Algorithmica and is apparently behind a paywall today. I found copies of the article in some universities’ websites (e.g. here and here) and, to be honest, I don’t know if they are legit because I don’t know if universities are allowed to provide some articles as part of their teaching activity. I’ll remove these links if they point to something unlawful, although it would be a shame considering how much people would need to really read that article in the first place!
-
The implementation in netlib is apparently different from the one in Fortune’s homepage, although I only checked this with
diffto be honest, so it might be only minor changes. I’m not even sure which of the two is the more updated one, so choose carefully if you want to reuse that code.